
DB & AWS Knowledge
MySQL / MariaDB 의 쿼리 실행 계획 (explain) 본문
해당 페이지에서는 MySQL / MariaDB 의 쿼리 실행 계획에 대해서 다룬다.
참조 페이지
https://dev.mysql.com/doc/refman/8.0/en/explain.html
https://dev.mysql.com/doc/refman/5.7/en/explain.html
https://mariadb.com/kb/en/explain/
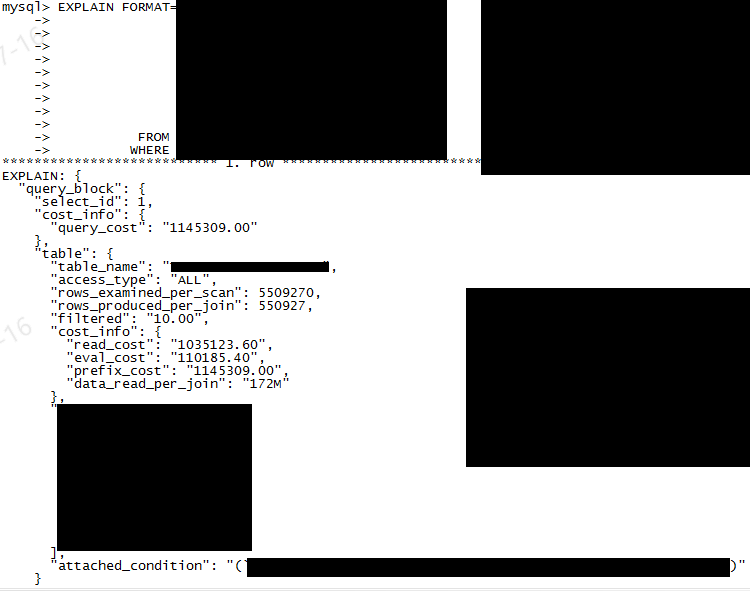
MySQL / MariaDB Explain 은 기본 명령어만 사용하여 실행 계획을 세울 시, 아래와 같은 결과를 보인다.
이를 바탕으로 Analyze 등의 옵션 명령어들을 사용 할 수 있다. (테이블, 컬럼정보는 보안으로 인하여 masking 함)

또한 테이블 형식으로 결과를 보이는 것 이외에 format=json 을 사용하면 cost 등의 기타 추가 정보를 볼 수 있다.
위의 결과에 대한 각 컬럼별 정보는 아래와 같다.
ID
MySQL / MariaDB 는 전체 구문에 대하여 실행 계획을 세울시 각 SELECT 구문별로 나누어서 실행계획을 세운다.
이 때, 각 SELECT 구문별로 메기는 번호 이며 Union 으로 결합한 Select 는 UNION 대상 테이블 이외에 결과에 따라 Null 로 행이 추가 될 수 있다.
Select Type
SELECT 실행 계획을 세울 시, 옵티마이저가 사용한 방법을 기재하는 컬럼이다.
- Simple
복수테이블이나, 서브쿼리가 없을 때 사용하는 단순 Select 방법이다.
- Primary
쿼리내부에 서브쿼리가 있을 시,
해당 서브쿼리 이외에 제일 먼저 조회 대상으로 삼는 select 쿼리에 쓰이는 방법
union 쿼리 사용시에는, union 대상 쿼리 중 제일 먼저 사용된 select 쿼리다.
- Union
위의 Primary 이외에 대상 쿼리들에 사용하는 Select 쿼리
- Dependent_Union
외부 서브쿼리의 조건값을 참조받아 사용되는 Select 쿼리
- Union Result
Union 에 따른 쿼리 결과
- Subquery
복합 쿼리 내부에 있는 서브쿼리 중 제일먼저 사용하는 select 쿼리
- Dependent_Subquery
위의 Dependent_Union 과 유사하게 외부 쿼리 결과값에 의존하는 서브쿼리
- Derived
FROM 뒤의 서브 쿼리 및 Inline View 등에 사용된 Select 쿼리
(즉, 메인 쿼리 이외에 파생 된 쿼리)
- Uncacheable Subquery
MySQL / MariaDB 에서는 반복 수행 쿼리 결과값이 동일한 경우에는 쿼리 캐시 부분에 해당 결과값을 저장하여
다른사용자들이 해당 쿼리를 수행시, 이에 대한 결과값을 빠르게 반환을 해준다.
이 방법이 사용되었을 경우에는 서브쿼리 결과값이 캐시가 되지않아서 쿼리가 수행 될 때 마다 매번 DB에서 수행을 해서 결과값을 얻어야 함을 뜻한다.
- Uncachable Union
위의 방법과 유사하게 Union 결과가 캐시되지 못하여 매번 Union 연산을 수행 해야 함을 뜻한다.
Table
제목 그대로 실행계획을 세울 대상 테이블을 보여준다. 실제 테이블 이외에 union (두 테이블간 조회), derive (테이블 조회시 파생된 조회 결과), subquery (서브쿼리 결과)
등도 실행계획을 세울 시, 임시 테이블 형식으로 만들었다는 것을 보여주도록 보여준다. (임시 테이블 뒤에 숫자는 위의 ID 를 뜻함)
Partitions
파티션 구성이 된 테이블은 옵티마이저가 조회할 데이터가 있는 파티션만 추적하여 조회하여 데이터 조회 부하를 줄일 수 있다. (파티션 프루닝 - Pruning)
이 때, 옵티마이저가 조회할 대상 파티션 테이블을 보여준다. 단, 위와 같이 파티션 구성이 안된 테이블은 NULL 로 나온다.
Type
조회 테이블들을 어떻게 결합 (Join) 하여 실행 계획을 세웠는지를 보여주는 컬럼이다.
보통 실무에서 단일 쿼리, 복합 쿼리 내 쿼리별 실행 계획에서 해당 내용을 확인하여
어떻게 테이블 데이터들을 조회하는지를 확인 하고 이를 통해 튜닝등을 고려 해 볼 수 있다.
단일 테이블 조회 때는 단일 테이블에 대해서만 실행 계획을 세우는 걸로 보면 된다.
실행 계획을 세우는 방법들은 아래와 같다.
- const
테이블 내 데이터를 조회시, 옵티마이저가 쿼리에 있는 조건절이 = 를 통하여 단 하나의 데이터를 조회 할 때 세우는 실행 계획이다.
- system
const 와 유사하지만, 데이터가 단 한개만 있는 테이블을 조회시 세우는 실행 계획이다.
- eq_ref
PK 나 Unique Index 등으로 정렬 혹은 참조 정보가 포함되서 있는 복합 테이블의 데이터를 조건절로 (=) 조회 하여
조건에 부합하는 단 하나의 데이터를 뽑을 때 세우는 실행 계획이다.
- ref
PK 나 Unique Index 이외의 인덱스로 참조 정보가 포함되서 있는 복합 테이블의 데이터를 조회 시
조건에 부합하는 모든 데이터를 뽑을 때 세우는 실행 계획이다.
- full text
인덱스중에 fulltext 인덱스를 설정한 테이블 조회시 사용하는 type 이다.
- index_merge
한개 혹은 그 이상 테이블을 조회시, 각 테이블마다 한 개 이상의 설정된 인덱스들을 조합하여
실행 계획을 세우는 방법이다.
- unique_subquery
subquery 사용 시, PK 나 Unique Index 같이 고유값을 가지는 데이터에 설정한 인덱스로
실행 계획을 세우는 방법이다.
- index_subquery
subquery 사용 시, PK 나 Unique Index 이외의 인덱스를 사용하여
실행 계획을 세우는 방법이다.
- range
인덱스를 통하여 특정 범위 내에서 데이터를 조회시에 사용하는 방법
- index
index full scan 으로써 index 내에 있는 모든 참조 값들을 조회 하는 방법
필요한 참조값만 조회 하지 않는다는 점에서 좋지 않은 실행 계획이다.
- all
table full scan 으로써 테이블 내에 있는 모든 데이터를 조회하는 방법
실행 계획이 가장 좋지 않은 방법이다.
Possible Keys
데이터를 조회하기 위해 어떤 옵티마이저가 테이블내에 어떤 인덱스를 사용 할 수 있었는지를
보여주는 컬럼이다.
Key
옵티마이저가 실제로 사용한 인덱스를 보여준다. Null 이면 인덱스를 사용하지 않은 것이다.
Key_len
인덱스를 사용시, 인덱스 내의 얼마나 많은 Byte 를 사용했는지 보여준다.
Ref
인덱스 내의 데이터를 찾기 위해서 테이블에서 어떤 컬럼을 참조했는지를 보여준다.
Rows
원하는 값을 찾기 위해 읽어 들여야 하는 (혹은 Analyze 로 실제 수행 시, 실제로 조회한) 데이터 개수를 보여준다.
Filtered
전제 테이블 데이터 대비 테이블 조회 조건으로 걸러진 (필터링 된) 데이터의 비율
Extra
위의 해당 사항 이외에 사용한 방법을 보여준다. 어떤 쿼리 및 테이블을 사용하여 조회할지에 따라
매우 다양한 방법이 있는데 여기서는 실무에서 흔히 보이는 내용들만 나열한다.
- Using Index
커버링 인덱스 (실제 데이터 조회 없이 인덱스 구조 조회만으로 데이터 정보 조회가 가능한 인덱스) 를
사용하는 방법이다.
- Using Index Condition
테이블을 조회할 때, 옵티마이저가 조회할 테이블 내에 인덱스만으로 원하는 데이터를 조회 할 수 있는지
아니면 table full scan 을 사용 해야 할 지를 판단 후, 인덱스로 조회가 가능하다면 스토리지 엔진에
where 조건으로 push 를 줘서 스토리지 엔진이 table full scan 을 피해
where 조건에 따른 데이터만 조회하게 하는 방법이다.
where 조건 (condition) 을 스토리지 엔진에 push 했다는 뜻에 따라 Index condition pushdown 이라고 명명된다.
사용하려면 DB에서 set optimizer_switch = 'index_contition_pushdown=on'; 을 사용해야한다
- Using Where
말 그대로 Where 조건절에 부합하는 데이터만 조회하는 방법이다.
인덱스를 통하여 필요한 데이터만 조회하지 않고, 해당 방법 없이
Table Full Scan 혹은 Index Full Scan 을 사용한다면 실행계획을 올바르게 사용하지 않을 확률이 높다.
- Using Filesort
메모리 혹은 디스크내의 모든 데이터를 정렬해서 조회하는 방법이다.
데이터가 많을 수록 부하가 매우 커지는 방법이다.
- Using Temporary
MySQL / MariaDB 는 데이터 조회 혹은 기타 작업 시, 내부적인 임시(temp) 테이블을 만들어서
해당 작업을 처리하는 경우가 있다. 이를 사용 했을 시, 나오는 방법이다.
물론 임시테이블을 새로 만드는 과정이 추가로 있다는 점에서
좋은 실행 계획은 아니다.
'MySQL > 성능 관련 지식' 카테고리의 다른 글
| MySQL, MariaDB 의 innodb_io_capacity 파라미터 설정 (0) | 2024.01.12 |
|---|---|
| MySQL latch 유형 - btr_search_latch (0) | 2023.06.23 |