
DB & AWS Knowledge
PostgreSQL / PPAS index 종류 본문
해당 페이지에서는 PostgreSQL / PPAS 에서 사용하는 인덱스 종류를 다룬다.
(참조 링크 : hub.packtpub.com/6-index-types-in-postgresql-10-you-should-know/)
(참조 링크 : postgresql.org/docs/13/indexes-types.html)
(참조 링크: 각 인덱스별 설명 사이트)
medium.com/postgres-professional/indexes-in-postgresql-5-gist-86e19781b5db, habr.com/ru/company/postgrespro/blog/446624/
habr.com/ru/company/postgrespro/blog/448746/
habr.com/en/company/postgrespro/blog/452900/
먼저 아래의 내용을 확인 전, 인덱스의 기본개념을 정리한 내용을 먼저 확인하고 보는 것을 권장한다.
2021.03.09 - [DB 관련 지식/DB 기본 개념] - 인덱스 (Index)
인덱스 (Index)
해당 페이지에서는 DB 에서 쓰이는 인덱스 개념에 대해서 알아본다. (참고 사이트) itholic.github.io/database-index/, ko.wikipedia.org/wiki/%EC%9D%B8%EB%8D%B1%EC%8A%A4_(%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%..
dbknowledge.tistory.com
현재 13버전 기준, PostgreSQL / PPAS 에서 사용가능한 인덱스는 크게 6종류다 : B-tree, Hash, GiST, SP-GiST, GIN, BRIN
B-tree
B-Tree 인덱스는 위의 인덱스 개념에서 설명한 구조와 동일하다. 또한 PostgreSQL / PPAS 는 연산자 [<, <=, =, >, =>] 로 데이터를 조회 시, 옵티마이저가 기본적으로 해당 인덱스를 사용하려는 실행 계획을 만든다.
Like 를 통한 특정텍스트로 시작하는 유사 텍스트 (Like 'foo%') 를 조회시에도 사용되는데 Like '%foo' 같이 앞부분부터 유사 텍스트로 시작하는 구문에는 사용되지 않는다.
locale (국가, 문화권에 따른 언어 인코딩 방식) 에도 영향을 받는데 ISO 기준 인코딩 표준 설정인 C 이외의 locale (ex : US 방식) 을 설정시에도 해당 인덱스를 활용 하지 못할 수 있다.
대소문자를 구분하여 조회할 수 있는 조건인 ILIKE 구문 사용시, 대소문자 구분을 사용하지 않은 텍스트를 조회한다면 이에 대한 인덱스를 사용하지 않을 가능성이 높다.
Hash
Hash 인덱스 또한 위의 인덱스 개념에서 설명한 구조와 동일하다.
GiST (Generalized Search Tree)
복합적인 지리학적 (geometric) 데이터를 조회하는데 매우 유용한 인덱스이며 내부 구조 예시는 아래와 같다.
(그림출처 : medium.com/postgres-professional/indexes-in-postgresql-5-gist-86e19781b5db)
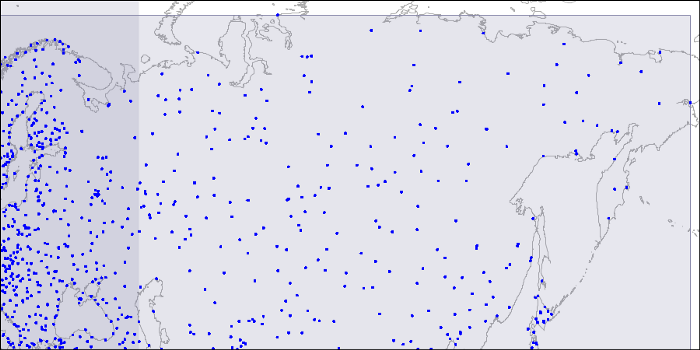
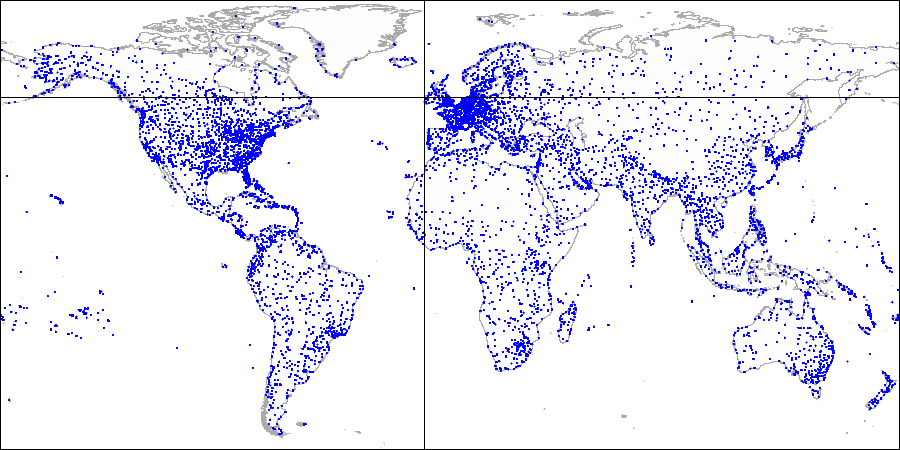
먼저 아래의 지도에서 특정 데이터 지점분포들을 여러개의 사각형으로 세분화 시켜 나눠본다.
각각의 사각형은 인덱스 페이지로써, 3단계 분할은 각각의 인덱스 페이지내에 최대로 저장할 수 있는 지점만큼을
저장시 나눌수 있는 분포다.
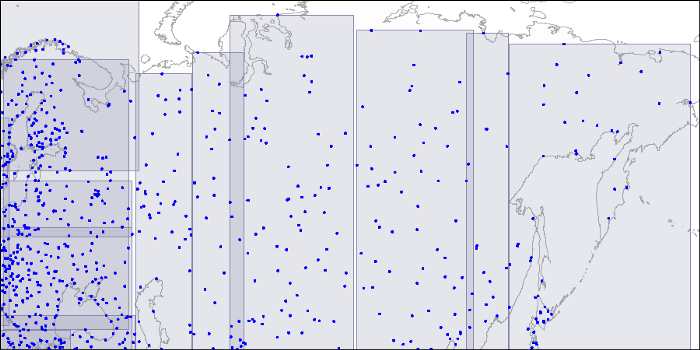

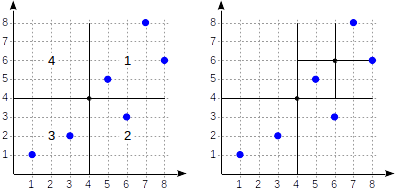
여기서 나뉘어진 하나의 사각형을 확대하여 살펴보면 아래와 같이 2차원 좌표 (x,y) 값으로 각 지점의 주소를 확인 해 볼 수 있다. 그러면 해당 좌표들로 메겨진 데이터들은 아래와 같이 DB에 저장 할 수 있다.
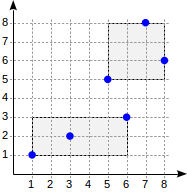
postgres=# create table points(p point);
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
postgres=# create index on points using gist(p);
이와 같이 해당 좌표들로 데이터를 저장 후, GiST 인덱스를 만들면 아래와 같은 구조로 데이터가 보관된다.
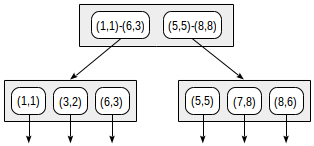
이와 같이 구성 후, 데이터를 조회해 보면 아래와 같은 실행 계획을 볼 수 있다.
postgres=# set enable_seqscan = off;
postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN
----------------------------------------------
Index Only Scan using points_p_idx on points
Index Cond: (p <@ '(7,4),(2,1)'::box)
(2 rows)
SP-GiST (Space Patitioning GiST)
위의 GiST 에서는 B-tree 같이 인덱스를 통하여 소량의 보관 데이터를 세분화 할 시, 위계적인 순서를 모두 따라야한다. 이를 좀 더 개선하기 위하여 도입된 개념이 SP-GiST 다. 위의 약자 그대로 위의 GiST 으로 분류한 공간을 또 공간 단위로 나누어 관리하는 개념이다.
이에 대한 인덱스 구조 예시를 들기 위하여 아래와 같은 quadtree (사진트리) 예시가 있다. 사진트리는 해당 인덱스에서 설정할 수 있는 유형 중 하나다.
(출처 : habr.com/ru/company/postgrespro/blog/446624/)
아래와 같이 세계 공항 예시 지도가 있다. 이 지도를 하나의 점을 중심으로 4분할로 지속적으로 나누어 본다.

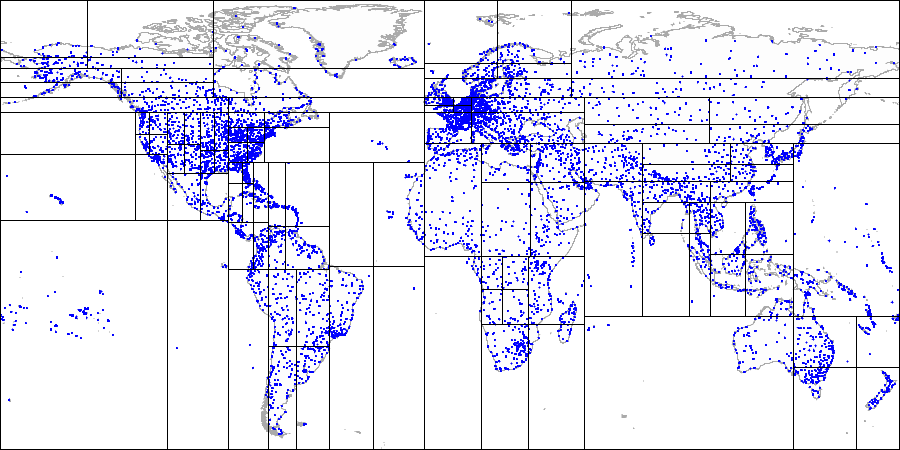
이렇게 4개의 공간으로 분할을 한 뒤, 1번 영역을 아래와 같이 확인한다.
분할된 1번영역을 보면 4개의 영역 중에서 데이터가 없는 공간이 있거나 경계 영역에 있는 데이터가 있다.
이와 같이 SP-GiST 인덱스 에서는 지속적으로 분할된 공간안에서 데이터 분포를 따라 아래와 같은 인덱스 구조를 만든다. GiST 와 비교해보면 분할 된 공간에서 첫번째 분할에서 유일하게 분류 되는 데이터 (6,3) 는 중간과정을 거치지 않고 바로 조회가 가능하도록 보관하고 분할된 공간 내에서 여러개가 데이터가 있을 시, 한개의 데이터를 (8,6) / (1,1) 기준삼아 다른 데이터들을 찾을 수 있도록 설정 했음을 알 수 있다.

이를 DB 내에서 구성을 해보면 아래와 같이 구성을 할 수 있다.
postgres=# create table points(p point);
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
postgres=# create index points_quad_idx on points using spgist(p);
또한 해당 분할방법 사용 할 수 있는 연산자정보 (quad_point_ops class)를 아래와 같이 확인 해 볼수 있다.
(사진트리 이외에 다른 방법으로 분할하는 방법에 따라 사용할 수 있는 연산정보는 각각 다르다.)
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 strictly left
>>(point,point) | 5 strictly right
~=(point,point) | 6 coincides
<^(point,point) | 10 strictly below
>^(point,point) | 11 strictly above
<@(point,box) | 8 contained in rectangle
(6 rows)
예시로 위의 구성에서 select * from points where p >^ point '(2,7)' 을 통하여 (2,7) 을 조회한다고 가정해보자.
조회시에 아래의 과정을 거친다.
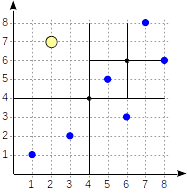
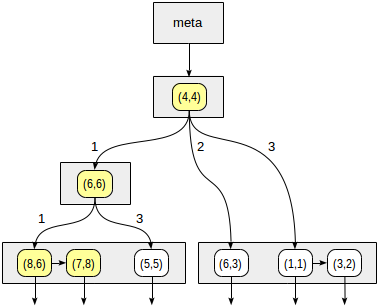
위의 노란색 영역을 보면 해당값은 분할된 영역의 첫번째에 있음을 알 수 있다. 이를 통하여 첫번째 영역에 있는 데이터로만 조회를 하게 된다면. 위와같이 인덱스 내의 첫번째 영역으로만 조회를 하면 데이터를 조회 할 수 있다.
실제 실행 계획은 아래와 같이 나온다.
postgres=# set enable_seqscan = off;
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
GIN (Generalized Inverted Index)
Full Text 조회에 두각을 나타내는 인덱스다. 기존 구조는 B-Tree 와 유사하나 페이지 저장구조가 조금 다르다.
예를 들어 아래의 테스트 데이터를 만든 후, 데이터를 기입 해 보자
postgres=# create table ts(doc text, doc_tsv tsvector);
postgres=# insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
postgres=# update ts set doc_tsv = to_tsvector(doc);
postgres=# create index on ts using gin(doc_tsv);이와 같이 데이터를 만들어 보면 Long Text 가 있는 것을 확인 해 볼 수 있다.
GIN Index 에서는 아래와 같이 위의 텍스트를 구조화하여 보관한다.
(해당 그림 게시자가 many 를 mani 로 잘못썼다.)

이와 같이 데이터를 table rows (TIDs) 단위로 보관하면서 각 row 의 주소값을 배정하여 보관하게 된다. (검은색 도형)
이를 Posting List 라 한다.
그래서 위의 정보를 조회하면 아래와 같은 구조로 저장됨을 알 수 있다.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------
(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4
(0,2) | How many sheets coul | 'could':4 'many':2 'sheet':3,6 'slit':8 'slitter':7
(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8
(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1
(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5
(2,1) | I slit sheets. | 'sheet':3 'slit':2
(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
(9 rows)
이렇게 살펴보면 여러번 나오는 sheet, slit, slitter 이외에 모든 어휘소에는 각 고유 TIDs 에 맞춰 배정되었음을 알 수 있다. 또한 각 페이지에 자주나오는 어휘소들을 배정했음이 보인다.
크기가 커서 텍스트 데이터를 각 페이지에 모든 정보를 넣을수가 없거나 여러 번 나오는 어휘소 등을 여러번 사용해야 할 시, GIN 인덱스는 해당 데이터에 대해서 Posting List 보다 더 큰 단위의 Posting 집합 (해당 어휘소를 가지고 있는 모든 TIDs 집합) 을 부여하는데 이를 Posting Tree 라고 한다.
해당 데이터의 어휘소 리스트와 개수도 알아볼 수 있다.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts
group by 1 order by 2 desc;
lexeme | count
----------+-------
sheet | 9
slit | 8
slitter | 5
sit | 2
upon | 1
mani | 1
whoever | 1
sleekest | 1
good | 1
could | 1
ever | 1
(11 rows)
하위 페이지를 들여다보면 B-Tree 류와는 다르게 하위페이지의 연결 방향이 양방향이 아닌 단방향임을 확인 할 수 있다.
실제로 조회를 할시에는 아래의 실행계획을 거치며 그림과 같은 쿼리 실행 계획을 세운다.
postgres=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
(4 rows)
위의 실행 계획을 자세히 보려면 아래와 같이 특수 함수를 사용하면 상세 조회 계획을 볼 수 있다.
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1 matching search query
@@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility)
(2 rows)
도식화 된 실행 계획은 아래와 같다. 우선 위의 many 는 pointing list 가 하나이므로 바로 찾을 수 있지만,
slitter 는 여러 문장에 거쳐서 나오기 때문에 Pointing Tree 에서 many 가 있는 문장의 TIDs 를 조회하게 된다.

이를 표로 나타내면 T F 여부로 해당 단어가있는 TIDs 를 조회한 후, 조회할 단어가 모두 있는 TID 를 선정 후, 결과를 나타내는 것을 알 수 있다.
| | | consistency
| | | function
TID | mani | slitter | slit & slitter
-------+------+---------+----------------
(0,1) | f | T | f
(0,2) | T | T | T
(1,2) | f | T | f
(1,3) | f | T | f
(2,2) | f | T | f
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc
---------------------------------------------
How many sheets could a sheet slitter slit?
(1 row)
이와 관련하여 실제 성능 개선을 이룬 사례의 링크도 참조하면 좋다.
medium.com/vuno-sw-dev/postgresql-gin-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EB%A5%BC-%ED%86%B5%ED%95%9C-like-%EA%B2%80%EC%83%89-%EC%84%B1%EB%8A%A5-%EA%B0%9C%EC%84%A0-3c6b05c7e75f
PostgreSQL GIN 인덱스를 통한 LIKE 검색 성능 개선
안녕하세요, 뷰노 SW 개발팀의 김병묵입니다.
medium.com
BRIN (Block Range Index)
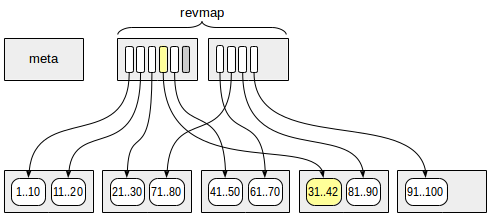
9.5 버전부터 도입된 인덱스 형태다. 각 데이터값을 개별적으로 B-Tree 구조와 달리, 특정 데이터의 주소값을 반영하기 위해 개별의 데이터를 추출하여 키워드로 쓰지 않고 단위 블록들에 속해 있는 데이터들의 최소값과 최대값만 추출하여 키워드로 구성한다.
그래서 특정 범위로 데이터를 조회하는 작업에서 매우 탁월한 성능이점을 보이며, 개별적으로 키워드 데이터를 저장할 필요가 없으므로 인덱스를 보관하는데 필요한 공간도 B-Tree 대비 적다.
하지만 반대로 불특정 다수의 데이터를 골라 내야하거나 Hash 등의 함수로 변환이 되는 데이터 조회 시에는 불리하다.
인덱스를 생성 시, 아래의 구조로 인덱스가 구성된다.
'PostgreSQL > 아키텍처 및 내부 구조' 카테고리의 다른 글
| PostgreSQL / PPAS DB Age (0) | 2021.04.16 |
|---|---|
| PostgreSQL / PPAS 기본 아키텍처 (Engine) (0) | 2021.03.19 |
| PostgreSQL / PPAS Lock 종류 (0) | 2021.03.08 |
| PostgreSQL / PPAS 트랜잭션 Isolation Level (0) | 2021.03.07 |
| PostgreSQL / PPAS MVCC (0) | 2021.03.07 |
