
DB & AWS Knowledge
Kafka 개요 본문
이 페이지에서는 대용량의 데이터를 처리할 목적으로 쓰이는 분산형 스트리밍 플랫폼 Kafka 의 개요 및 기본 아키텍터에 대하여 다룬다.
이 페이지는 아래의 페이지들을 참조하여 작성한다.
[2] https://twofootdog.tistory.com/86
[4] https://www.scaler.com/topics/kafka-architecture/
Kafka 는 무엇인가?
Kafka 는 직장인 소셜 네트워크 플랫폼인 링크드인 (LinkedIn) 에서 지속적으로 증가하는 대규모의 데이터를 처리하는데 사용되는 데이터 파이프라인 수단으로 사용되기 시작되었으며, 2011 년에 Apache 에 오픈소스로 공개되었다.
Kafka 의 특징
Kafka 는 크게 아래의 특징을 가지고 있기 때문이다.
- 데이터 관리의 간소화
기존의 애플리케이션, DB 와 같이 각 역할이 나뉘어진 서버구조에서는 아래 화면과 같이 서버별로 데이터를 각각 보관하면서 이후 서비스 확장이 계속되면 복잡도가 크게 증가한다. 이 상황에서는 장애가 발생시에 어디에서 장애가 발생했는지에 대해서도 추적하기가 점점 어려워진다.
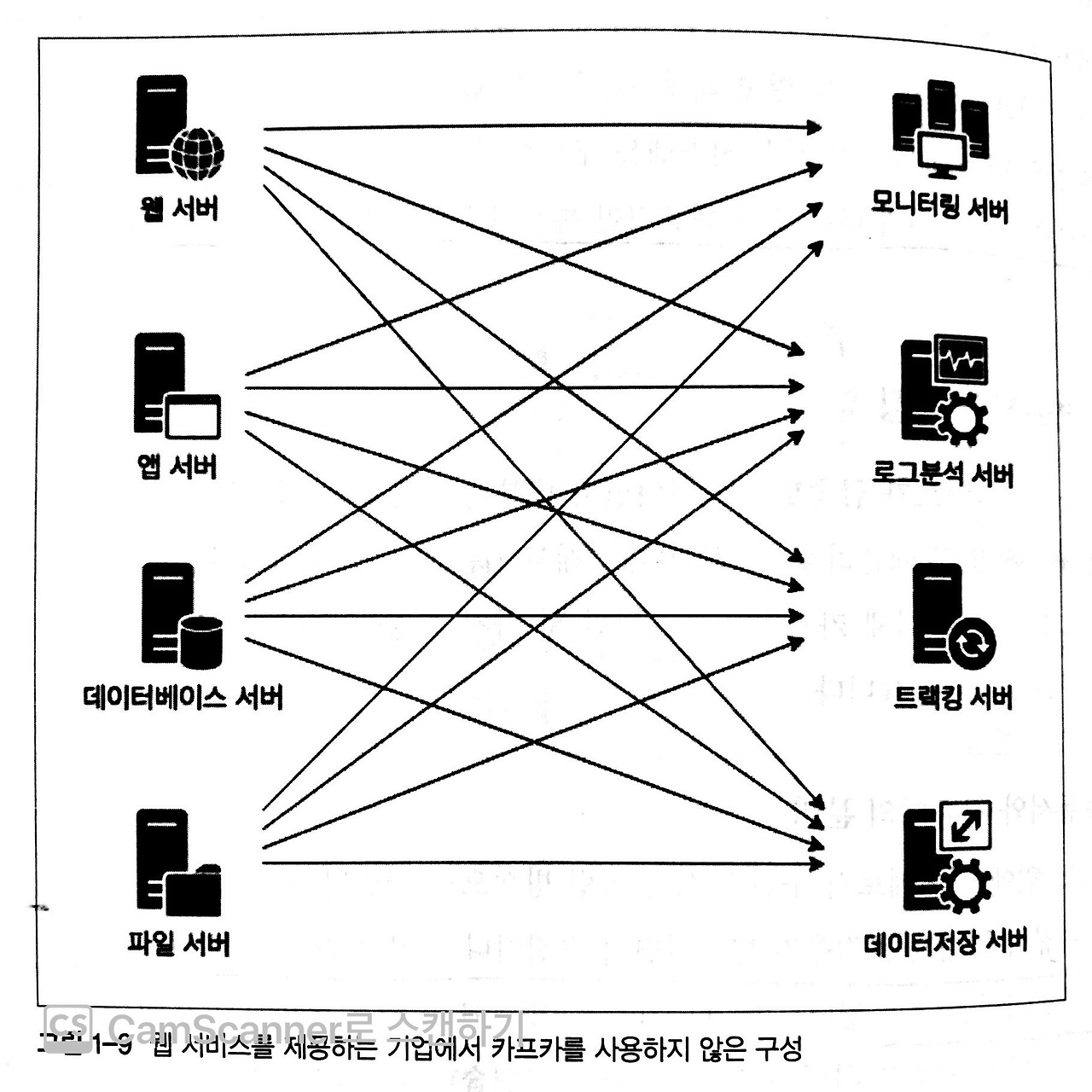
이 때, Kafka 를 이용하면 아래와 같이 데이터 처리 point 가 Kafka 한곳으로 집중되어 모인 후, 종단에 다다르기 때문에 데이터 및 장애 관리가 매우 유용해 진다.
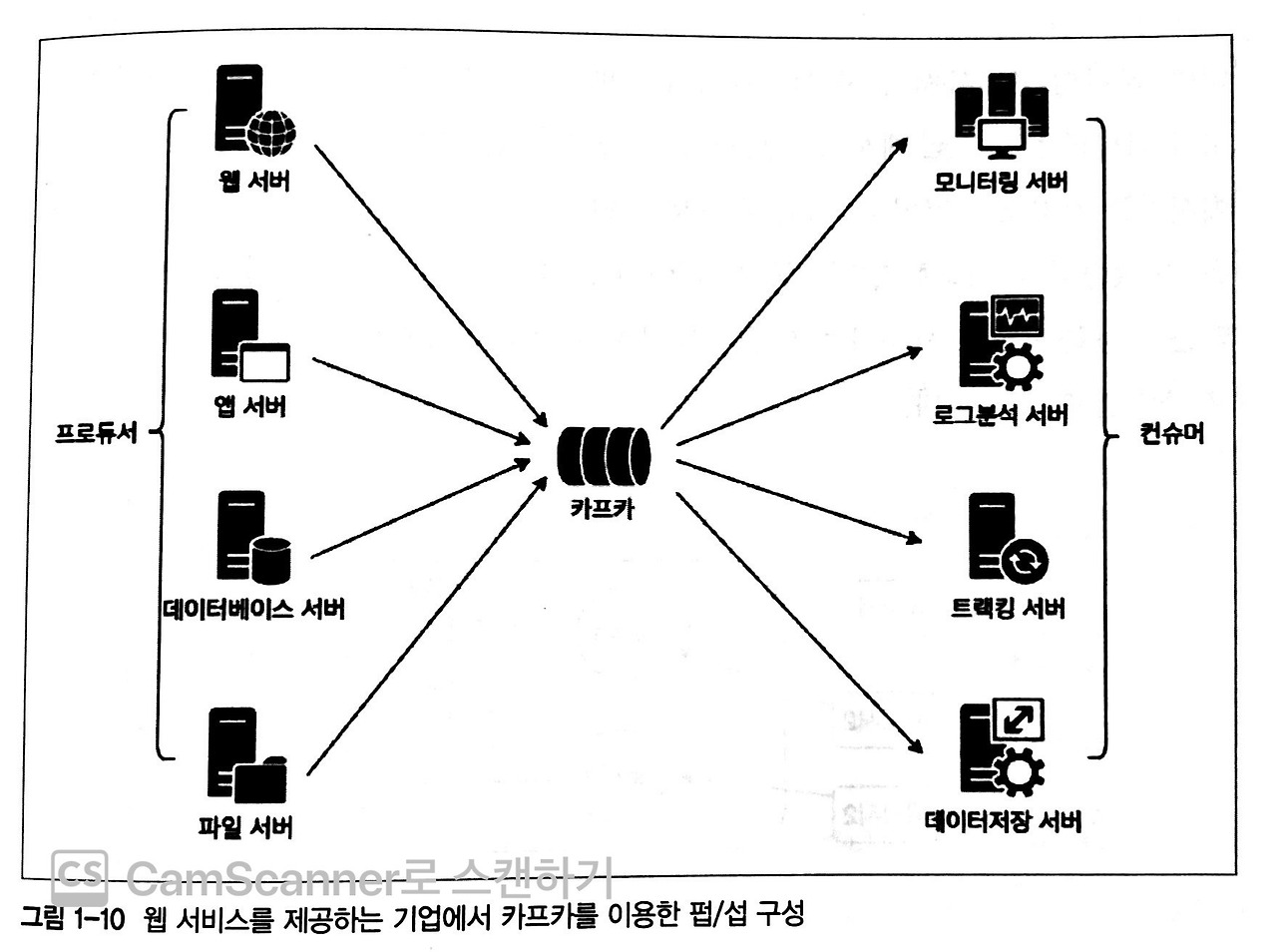
- 뛰어난 이벤트 스트리밍 성능
이벤트 스트리밍은 데이터가 발생하는 즉시 실시간으로 캡처하고, 저장하며, 처리 및 분석하여 다양한 시스템이나 애플리케이션에 전달하는 데이터 처리 방식을 뜻하며 Kafka 가 만들어 질 때, 추구했던 대표 장점이다. 이러한 장점을 통해 사용자는 데이터가 발생하는데로 다른 서비스등과 쉬운 연동, 빠른 데이터 분석을 수행 할 수 있다.
- Pub/Sub 모델
Pub/Sub (Publish/Subscribe) 모델은 Publisher 가 데이터를 생성하면 Subscriber 가 이를 받아 소비하는 구조에 중간 매게체를 추가하여 데이터를 처리하는 서비스 모델을 뜻하며 위의 화면에서 짐작할 수 있듯이 Kafka 가 바로 이러한 특징을 지닌다. Kafka 에서는 Publisher 는 Producer, Subscriber 는 Consumer, 중간 매게는 Broker 로 지칭된다. 이 때, Broker 는 Kafka 내부에 여러개로 구성되면서 Kafka Cluster 로 묶이게 된다.
이러한 모델을 사용하면 중간 매게인 broker 만 관리하면서 아래의 장점을 가지게 된다.
- 확장성
Kafka 에서 Broker 의 개수를 늘리면서 지속적으로 늘어나는 데이터 처리량에 빠른 대응이 가능하다.
- 비동기식 데이터 처리
Broker 에는 Message Queue 라 하여 Producer 에서 오는 데이터를 임시 보관 할 수 있는 공간이 있고 이에 따라 Consumer 에 데이터를 바로 보내지 않으면서 비동기식으로 서비스를 운영 할 수 있다.
- 빠른 장애 복구
Broker 가 여러개면 고가용성을 통해 특정 Broker 가 이용불가 상태가 되도 다른 Broker 가 데이터처리를 할 수 있다. 이에 따라 장애 발생시에도 빠른 복구를 추구 할 수 있다.
- 디스크에 있는 파일시스템에 데이터 보관
메모리에 데이터가 보관되면 문제가 발생 시, 휘발될 수 있는 in memory 구조와 다르게 Kafka 는 데이터를 파일시스템에 보관함으로써 장애 발생시에도 데이터를 계속 보존 할 수 있다. RDBMS 에 익숙한 사용자에게는 ACID 중, duribility 의 특징을 가지고 있다고 보면 이해하기 쉽다.
'Kafka, MSK, Kinesis > 아키텍처 및 내부 구조' 카테고리의 다른 글
| Zookeeper 개요 (0) | 2025.05.24 |
|---|---|
| Kafka 기본 요소들에 대한 추가 이해 - 2 (0) | 2025.05.21 |
| Kafka 기본 요소들에 대한 추가 이해 - 1 (0) | 2025.05.21 |
| Kafka 데이터 예시 (0) | 2025.05.15 |
| Kafka 를 공부하기 위해 필요한 기본 용어들 (0) | 2025.05.12 |